
Feed43 + iFTTT:RSS种子制作与推送的简明教程
Feed43.com是一个广为人知的RSS种子生成网站,它可以将普通的、没有RSS源的网页生成RSS源,以供狗耳朵或者RSS阅读器推送、订阅和阅读。但是,通过百度搜索的feed43食用教程大多数太过简单,对具体的制作步骤含混带过,让普通人难以理解和学习。官方教程倒是详细,但是很多计算机术语,加上过于简单的例子带来了非常高的门槛。
这篇文章主要是谈代码,我将简要叙述一下大概思路,然后通过实例来保证讲解简单易懂,希望可以帮到那些需要使用此网站但又望而却步的朋友们。
Step 0:注册Feed43账号
Feed43的网站是http://feed43.com/,推荐注册一个账户,这样自己创建的RSS就会更方便查询和调用。单击主页右上角的 CreateAccount 即可创建。
官方教程单击 Learn more →即可查阅,在主页单击 Create your own feed 即可创建RSS种子,在同意协议后继续。
Step 1:载入
输入你想要制作的网站的网址,比如这样:

编码方式(Encoding)不填即可,如果下一步出现乱码,则单击浏览器返回按钮返回这一步,在浏览器打开该网页,Chrome等同内核浏览器按住Ctrl+U打开view-source模式查看源代码,在下图这一行找到编码方式。

可能在国内的关系,Reload后的时间有些久,稍等下会出现下图。

Step 2:查看网页源代码并找到我们想提取的信息
如果Page Source的内容你看不懂,请自行前往w3c school
HTML和CSS部分补习,推荐全部学完。
源码对照网站,比如说,我想要这部分的内容:
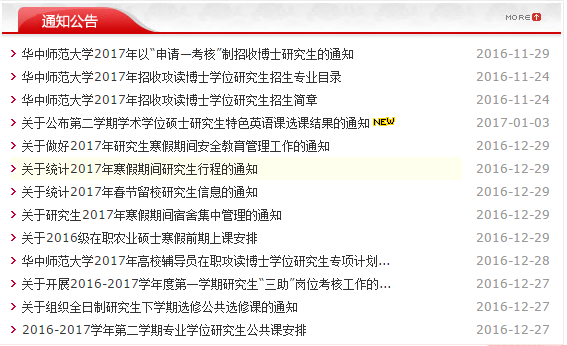
我的第一步,就是在网站源代码找到相应的字:
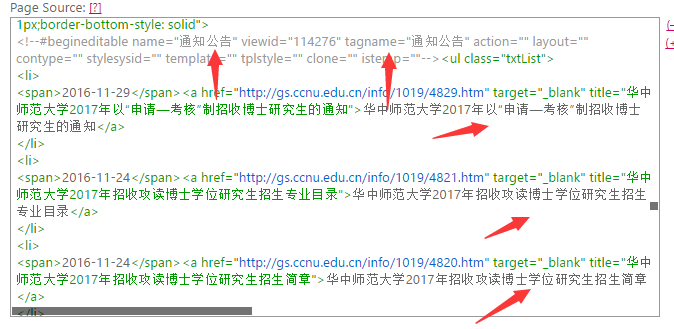
然后进行下一步。
推荐在下一步之前阅读这个网页:http://feed43.com/understanding-patterns.html,。
Step 3 :输入匹配规则,调试程序
- Global Search Pattern 指的就是指定在网页搜索的范围,不填即可,它会自动全站搜索。
- Item (repeatable) Search Pattern* 指的是你想要匹配和提取的内容。
打个比方,我们想要在大海里捞鱼,首先要确定捞什么鱼。<span><li></span> 等这些单书名号里面的东西就像是鱼的标签。<span>和</span>之间的内容就是鱼的主体,我们只需要告诉机器识别<span></span>这个鱼的标签即可。
如果你不明白这一段,请前往w3c school自行学习HTML知识
但是,一个网站中有很多<span>,我们仅仅需要其中一部分,这可怎么办?也很简单。首先我们需要了解,网站的内容就是<html>和</html>之间的部分,而<span>和</span>等则是被包裹在<html>和</html>内的,就像html的儿子。在“<span><p>内容</p></span>”这个例子中,p标签则是span的儿子。如果遇到长相相同的儿子,而我们又需要辨别其中一个的话,只需要找他爸就可以了,如果这两个儿子的爸长得也一样,那么就继续往上找。如果都是一个爸,那么需要采用其他方法提取。
搜索的代码我填的是这个:
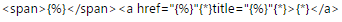
解释一下意思。一般来说,出现在<span></span>之间的,就是我们要提取的内容,对于这部分文字,我们用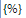 代替。因为我们要继续提取链接,所以出现了
代替。因为我们要继续提取链接,所以出现了<a></a>的标签。对于链接标签的属性也可以提取,其属性被放在第一个<>内,href指的是链接的地址,一般长这个样子:<a href="http://gs.ccnu.edu.cn/xj/tzgg1.htm">,只需要把http://gs.ccnu.edu.cn/xj/tzgg1.htm替换成即可,记得“”不要忘记加上。{*}是一个很神奇的东西,这个东西就像502,可以把各个断了的代码粘起来。比如我们要提取
<a href="http://gs.ccnu.edu.cn/info/1019/4821.htm" target="_blank" title="华中师范大学2017年招收攻读博士学位研究生招生专业目录">
这个标签里的href属性和title属性,但是target不需要,那么就直接忽略不写,但是,如果不写的话,对于计算机而言,我们给他的指令就相当于
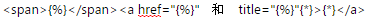
它不会理解残缺不全的后一段话,所以,我们有必要告诉机器,从上一段结束的地方继续进行,所以就用{*}来粘合两者。对于一切我们不需要搜索的东西都可以使用这个标志来代替。比如下文出现在<a></a>之间的{*}来代替不需要的文字。但是,如果我们要提取这段文字的话,就需要把它换成了。
点击Extract会开始提取,下面是结果,如果结果不是自己需要的,比如多了些或者出现一些奇怪的字符,自己调整下代码,或者前往w3c school进一步补习知识,总而言之,这部分调试的过程需要很久,很花时间,如果没有基础的话,建议耐心一些,我第一次在这里尝试了半个晚上,最够才搞定。
对于上文提到的网站,因为提取的结果多了,但是在提取代码里不好继续改,那么就可以改搜索的代码,就是之前我们说可以不用填那个框,对于这个网站,我填的是:

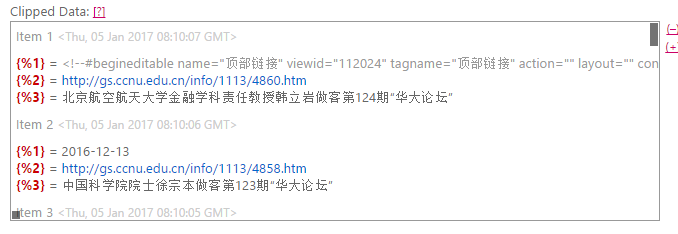
这里的item就是我们提取的条目,就是网站提取的内容,因为有三个在代码里,所以就有三个不同的内容输出。
Step 4:补充和完善RSS信息
下一步,完善RSS内容。
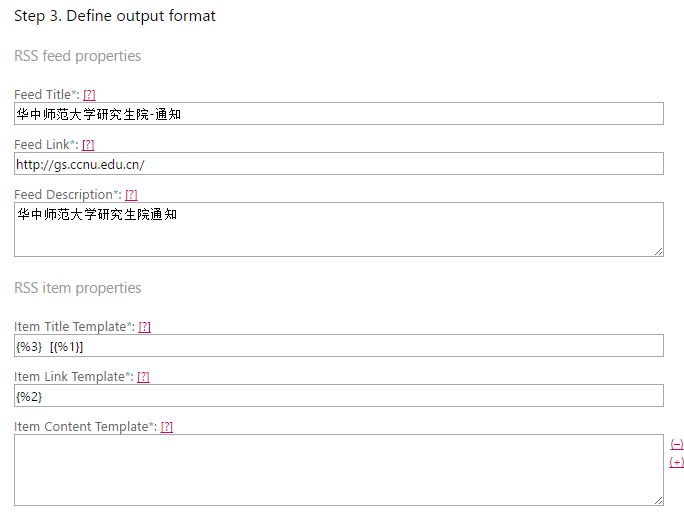
关于RSS item properties 即RSS输出,选择3作为标题,2作为链接,因为FEED43并不能打开网页输出全文,加上网站没有关于内容的说明,所以我选择不输出内容,所以我的RSS只有标题和链接,它对我的作用就是通知,我会点开链接自己上网站查看。
如果需要进一步获取全文,请参考*《使用huginn来获取RSS全文》*这篇文章。
最后,再给几个我做好的RSS,希望大家可以多练练手,找找感觉。
比如:http://gs.ccnu.edu.cn/xj/tzgg1.htm 这个网页,我的搜索代码是:
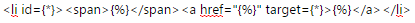
对于
http://www.zimuzu.tv/search?keyword=%E7%9C%9F%E5%AE%9E%E7%9A%84%E4%BA%BA%E7%B1%BB&type=subtitle
这个网站,我的搜索代码是:
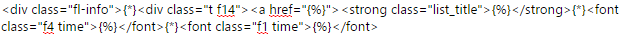
Step 5:设置iFTTT
打开ifttt.com,注册或者登录,点My Aapplets,右边按钮 New Applets, THIS 选择Feed,填入你想要被提醒的RSS源,接下来选择match你的关键字或者只要RSS有更新就提醒,比如我选择有更新就提醒,选第一个选项,填入一个RSS地址,比如这个是我自制的RSS,
One每日推送 http://feeds.feedburner.com/onedaily
That 可选有很多,比如iOS的通知,或者保存到Pocket,或者给你发一个邮件,或者发新浪微博,或者slack,比如,我选择slack,下面是结果。

附:iFTTT这种服务在天朝早晚有一天是要完蛋的,所以我用了自己的Huginn作为替代,这是一个更加强大的、能够在自己服务器上跑的开源版本的iFTTT,其代码托管在Github,目前中文资料还很少,欢迎大家踊跃体验。
CM 2016 于武昌
© 本文首发于blog.mazhangjing.com,转载请先联系作者,保留相关权利。