
自动语音报告记录:使用阿里云一句话识别 API 构建
本文介绍了使用阿里云的一句话识别 API,使用 Java Sound API 和 JavaFx 进行的语音报告识别自动记录:自动的在被试语音报告数字的时候记录其回答的结果。实现使用了多线程技术,因为在录制声音、使用 Netty 发送语音到阿里云服务器、语音结果同义词转换和解析、语音结果展示方面都存在各种并发问题,经过优化,本实现的语音识别率(85% 可用)可满足需要。
示意图如下:
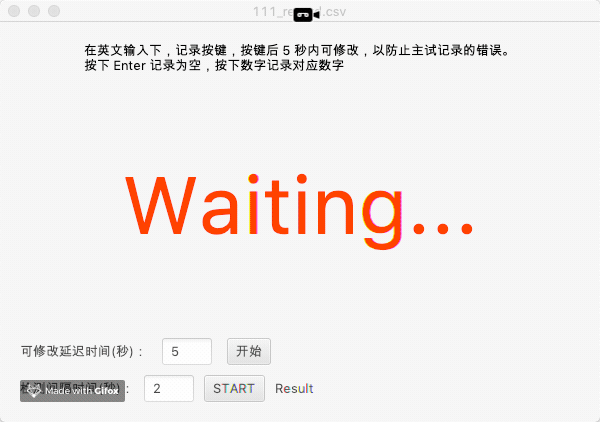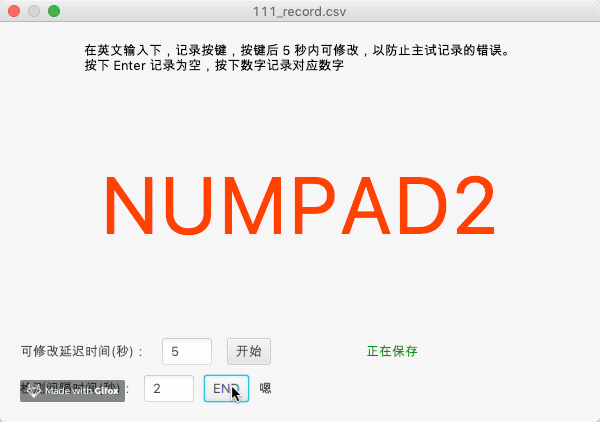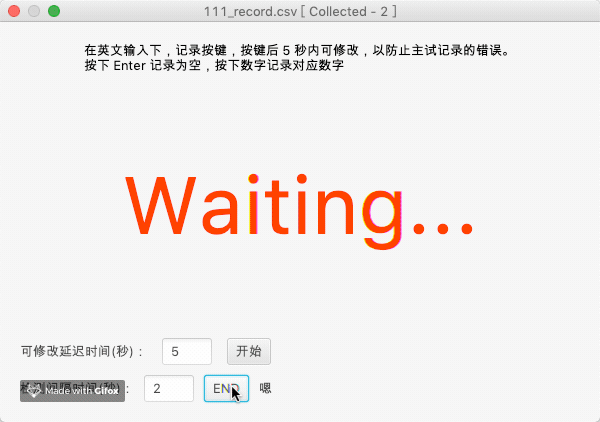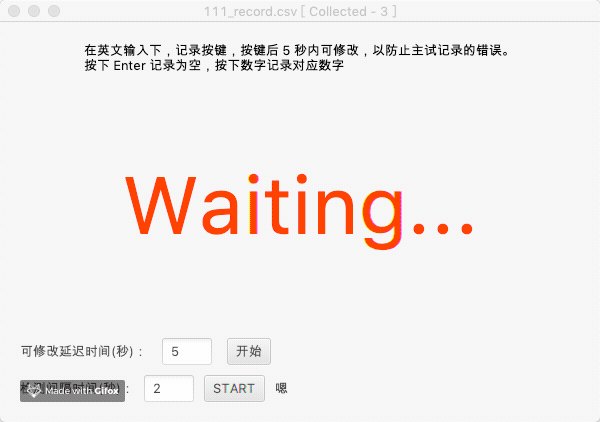
本识别程序还可以附带同义词解析,如下是一个示例,程序会读取 words.yml 文件以确定字词匹配,当同音字发生的时候,自动确认是被试想要报告的数字:
two:
- 二
- 额
- 耳
three:
- 三
- 山
- 伞
four:
- 四
- 思
five:
- 五
- 无
- 物
six:
- 六
- 流
- 刘
语音识别的使用和封装
API 简单介绍
阿里云的 API 提供了上传文件、流,通过轮询来返回结果的方式进行识别和翻译。其包含两大部分,其 pom 依赖如下:
<dependency>
<groupId>com.alibaba.nls</groupId>
<artifactId>nls-sdk-long-asr</artifactId>
<version>2.0.3</version>
</dependency>
<dependency>
<groupId>com.alibaba.nls</groupId>
<artifactId>nls-sdk-short-asr</artifactId>
<version>2.0.3</version>
</dependency>
简而言之,其一是处理短音频的(nls-sdk-short-asr),其二是用来进行大段翻译(nls-sdk-long-asr)的。
对于每种产品,API 都可以自动的将中文数字翻译为英文、可以智能断句、设置采样率、音频编码格式、控制发送速率,可选在中途或者结束后返回识别结果。
目标问题分析
阿里云提供了语音的识别 API,自然语言处理的 Java 接口包含两类,其一用来识别短句子,其二用来翻译长内容。在产品中,其分别被称之为一句话识别和通用语音识别,可以接受来自文件的流,或者来自实时录音的流。
我想要解决的问题是,当被试报告数字的时候,能够尽快的捕获和翻译其语音信息,并且转换为相应的数字。因为记录程序和实验程序是分开的,且实验程序每个 trial 的时间是根据被试决定的,因此,要尽可能快的收尽可能多的语音样本,发送到阿里云的服务器并且获取结果。
在这样一种需求下,一句话识别 Nls API 可以很好的解决问题,并且存在两种解决方案:
其一:每 2 s 收集语音样本,并且将这 2 s 的样本作为流发送到服务器,如果返回的内容不对应数字,则抛弃,重复这个过程。这种方式的问题是,每次都需要打开和关闭一个 Netty 的 Session,虽然总体而言,这并不影响/阻塞程序的运行。
其二:直接使用一个和语音输出耦合的流,并且阻塞阿里云 API,这样可以由阿里云 API 控制发送流中信息的频率,每次从流中取出一部分发送,这样的设计不用重复的在 Java 虚拟机中新建流,捕获音频,传输到流,关闭流这样的操作,性能更好。但是这种实现的问题在于,其 API 会将所有时间发送的所有信息作为一句话,并且在最终结束之前不会返回最终结果,虽然可以自动分行并且返回中间结果,但是,问题在于,每次返回中间结果都是从最开始录音的部分开始的,因此,为了获取数字,需要将一次的中间结果减去上一次的中间结果,这看起来也不难,但是,当识别的时间长达 2 个小时的时候,这显然不是什么好的选择。
其实最好的解决方案应该是,利用方法二,每隔 5 分钟重新建立一次连接,在每次连接中,使用中间结果。这种方案节省了性能开支,但是带来了一定的复杂性。
API 存在的陷阱
需要注意,上传流的话,文件转成 AudioInputStream 上传即可。而音频,可以收集并且通过 ByteArrayOutputStream、Byte[]、ByteArrayInputStream 包装成为 AudioInputStream 来上传。
ByteArrayOutputStream stream = getStreamFromMixer(targetDataLine);
byte[] bytes = stream.toByteArray();
logger.debug("After get Line");
ByteArrayInputStream bi = new ByteArrayInputStream(bytes);
或者采用实时语音:
AudioInputStream audioInputstream = new AudioInputStream(targetDataLine);
此外,文件或者别的流,不能直接通过 AudioSystem 的 getAudioInputStream 来直接通过流的构造器获得,要手动构造 AudioInputStream,传入帧数来创建 AuidoInputStream(如果需要 AudioInputStream 的话,这里直接使用的是 ByteArrayInputStream)。
需要注意,选择音频格式的时候,要根据阿里云的网站选择:16 bit 或者 8bit,此外需要注意,Java API 的 AduioFormat 需要设置 big-edian 为 false,阿里云使用的是 little-edian,虽然文档中没有说,但是如果使用默认的 big-edian,那么显然无法识别出任何有价值的内容。
private static final AudioFormat format = new AudioFormat(16 * 1000, 16, 1, true, false);
TargetDataLine targetDataLine = AudioSystem.getTargetDataLine(format);
targetDataLine.open();
targetDataLine.start();
具体的实现代码
根据方案一,在开始识别后,会先启动一个控制终止线程,直接睡到 2s后,然后主线程去打开 TargetDataLine,并且通过 buffer 将 Line 上的数据写入到一个 ByteArrayOutputStream 中,主线程此时被阻塞。当控制线程在 2s后苏醒,控制主线程停止收集。这时候,主线程进入下一步,将此 BAOS 中的数据 byte[] 通过包装成为 ByteArrayInputStream,然后交给 Nlc 上传到阿里云服务器识别,识别发生在单独的识别线程,其不阻塞主线程,其会在 n s后得到结果,执行对应的回调函数。这段代码循环往复的执行,除非终止次过程。
其核心代码如下:
public void doRecognition(int eachRecognitionDurationSeconds) throws LineUnavailableException, IOException {
TargetDataLine targetDataLine = AudioSystem.getTargetDataLine(format);
targetDataLine.open();
targetDataLine.start();
while (!stopRecognitionMark) {
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(eachRecognitionDurationSeconds);
} catch (InterruptedException e) {
e.printStackTrace();
}
logger.debug("Set StopMark to true");
stopCollectSound = true;
}).start();
ByteArrayOutputStream stream = getStreamFromMixer(targetDataLine);
byte[] bytes = stream.toByteArray();
logger.debug("After get Line");
ByteArrayInputStream bi = new ByteArrayInputStream(bytes);
new Thread(() -> this.process(bi)).start();
bi.close();
}
targetDataLine.stop();
}
private ByteArrayOutputStream getStreamFromMixer(TargetDataLine targetDataLine) throws IOException {
logger.debug("Start Record....");
ByteArrayOutputStream os = new ByteArrayOutputStream();
byte[] buffer = new byte[10000];
stopCollectSound = false;
int c;
while (!stopCollectSound) {
c = targetDataLine.read(buffer, 0, buffer.length);
if (c > 0) {
os.write(buffer, 0, c);
}
}
os.close();
logger.debug("Stop Record...");
return os;
}
语音和 JavaFx GUI 的整合
抽象的 Box 组件
在 JavaFx 中,自然所有的这套流程都是要放在单独的线程中的,称之为语音线程。其中根据上文,语音线程派生出声音收集控制线程,以控制在语音线程上阻塞的声音收集过程、远程语音解析线程,当其返回结果后回调已经定义好的函数执行,这里实际上用来显示结果到 GUI 界面,并且计算匹配,如果匹配,则模拟按下按键过程,以记录一个 trial 的结果。回调函数使用了同步锁,以防止共享逻辑导致的问题。此外,回调中的结果过滤并没有使用 JavaFx 的 SimpleObjectProperty,因为显然后者存在并发问题,当 set 一个值的时候,可能绑定在其上面的 Listener 无法调用执行(可能因为其 set 并不在 JavaFx GUI 线程上?)
VoiceRecognizerBox 核心代码如下:
class VoiceRecognizerBox(appKey:String, token:String) extends HBox{
val START = "START"
val END = "END"
val spaceLabel = new Label("检测间隔时间(秒):")
val spaceTime: TextField = {
val t = new TextField(); t.setPromptText("检测间隔时间(秒)"); t.setText("2")
t.setPrefWidth(50); t
}
val regResultString = new SimpleStringProperty("Result")
val regResult: Label = {
val t = new Label(); t.textProperty().bind(regResultString);t
}
var recognizer: AliVoiceRecognizer = _
var completedConsumer: Consumer[SpeechRecognizerResponse] = _
val controlBtn: Button = {
val t = new Button(START); t.setOnAction(_ => {
doAction()
}); t
}
getChildren.addAll(spaceLabel, spaceTime, controlBtn, regResult)
this.setAlignment(Pos.CENTER)
this.setSpacing(10)
def endSetStatus(): Unit = {
controlBtn.setText(START)
recognizer.requestShutdown()
}
def startSetStatus(): Unit = controlBtn.setText(END)
def startRecognizer(): Unit = {
recognizer = new AliVoiceRecognizer(appKey, token)
if (completedConsumer != null)
recognizer.completedConsumer = completedConsumer
new Thread(() =>
recognizer.doRecognition(spaceTime.getText.trim.toInt)).start()
}
def doAction(): Unit = {
if (controlBtn.getText == START) {
Platform.runLater(() => startRecognizer())
startSetStatus()
} else endSetStatus()
}
def setFinishCallbackAction(op: SpeechRecognizerResponse => Unit): Unit =
completedConsumer = (t: SpeechRecognizerResponse) => op(t)
def setAfterBtnClickedBeforeRecognizerStartedAction(op: => Unit): Unit = {
controlBtn.setOnAction(_ => {
if (controlBtn.getText == START) op
doAction()
})
}
def requestShutdown(): Unit = if (recognizer != null) recognizer.requestShutdown()
}
整合到 Recorder 记录器
class Recorder(mainStage:Stage, showNoBtn: Boolean = false) {
private[this] val logger = LoggerFactory.getLogger(getClass)
import Utils._
val key = new SimpleStringProperty("Waiting...")
var saving = false
val waiting: TextField = {
val t = new TextField("5"); t.setPrefWidth(50); t
}
val edit = new Label("检测到修改")
val save = new Label("正在保存")
val enter = new Button("开始")
val data = new ArrayBuffer[(Instant,String)]()
var fileName: String = if (showNoBtn) "NoName_record.csv" else showAlertAndGetName
val voiceBox = new VoiceRecognizerBox("PZiaqW1PVQE4","f6860ddbd72643a29")
voiceBox.setFinishCallbackAction(resp => {
val res = resp.getRecognizedText.trim
Platform.runLater(() => {
voiceBox.regResultString.set(res)
tryHint(res.trim)
})
})
voiceBox.setAfterBtnClickedBeforeRecognizerStartedAction {
logger.info(s"Reload Recognizer File from $configLoadFile now...")
loadWordsToGroup(configLoadFile)
}
var g2: Array[String] = _
var g3: Array[String] = _
var g4: Array[String] = _
var g5: Array[String] = _
var g6: Array[String] = _
val configLoadFile: Path = Paths.get(System.getProperty("user.dir") + File.separator + "words.yml")
val root: Parent = {
val pane = new BorderPane()
val info = new Text()
pane.setTop(info)
val keyPressed = new Label("")
keyPressed.textProperty().bind(key)
keyPressed.setTextFill(Color.RED)
keyPressed.setFont(Font.font(80))
pane.setCenter(keyPressed)
val waitingLabel = new Label("可修改延迟时间(秒):")
val allBox = new VBox(); allBox.setSpacing(10); allBox.setAlignment(Pos.CENTER_LEFT)
val funcBox = new HBox(); funcBox.setAlignment(Pos.CENTER_LEFT); funcBox.setSpacing(15)
voiceBox.setAlignment(Pos.CENTER_LEFT)
allBox.getChildren.addAll(funcBox, voiceBox)
info.textProperty().bind(new SimpleStringProperty("在英文输入下,记录按键,按键后 ")
.concat(waiting.textProperty()).concat(" 秒内可修改,以防止主试记录的错误。\n" +
"按下 Enter 记录为空,按下数字记录对应数字"))
edit.setTextFill(Color.RED)
edit.setVisible(false)
save.setTextFill(Color.GREEN)
save.setVisible(false)
funcBox.getChildren.addAll(waitingLabel, waiting, enter, edit, save)
BorderPane.setAlignment(info, Pos.CENTER)
BorderPane.setMargin(info, new Insets(20,20,20,20))
BorderPane.setMargin(allBox, new Insets(20,20,20,20))
pane.setBottom(allBox)
pane
}
val scene = new Scene(root, 600, 400)
val stage: Stage = initDataStage(mainStage, scene)
stage.setTitle(fileName)
scene.setOnKeyPressed(e => {
withTimeAndSaveKeyCode(e.getCode)
})
waiting.textProperty().addListener {
enter.requestFocus()
}
def loadWordsToGroup(path: Path): Unit = {
val map = VoiceRecognizerBox.readYamlToKeyVoiceMatchMap(path)
import collection.JavaConverters._
g2 = map.getOrDefault("two",List("二","额","啊").asJava).asScala.toArray
g3 = map.getOrDefault("three",List("三","伞","山").asJava).asScala.toArray
g4 = map.getOrDefault("four",List("四","是","事").asJava).asScala.toArray
g5 = map.getOrDefault("five",List("五","无","物","我").asJava).asScala.toArray
g6 = map.getOrDefault("six",List("六","哎呦","呦","没有").asJava).asScala.toArray
}
private[this] def tryHint(from: String): Unit = {
synchronized {
println("Try Hit " + from)
from match {
case i2 if g2.exists(g => i2.contains(g)) => withTimeAndSaveKeyCode(KeyCode.NUMPAD2)
case i3 if g3.exists(g => i3.contains(g)) => withTimeAndSaveKeyCode(KeyCode.NUMPAD3)
case i4 if g4.exists(g => i4.contains(g)) => withTimeAndSaveKeyCode(KeyCode.NUMPAD4)
case i5 if g5.exists(g => i5.contains(g)) => withTimeAndSaveKeyCode(KeyCode.NUMPAD5)
case i6 if g6.exists(g => i6.contains(g)) => withTimeAndSaveKeyCode(KeyCode.NUMPAD6)
case _ => println("No match for Hit " + from)
}
}
}
private[this] def showAlertAndGetName: String = {
val alert = new TextInputDialog()
alert.setContentText("输入被试编号")
alert.setHeaderText("将保存被试回答到 编号.csv 中")
alert.showAndWait()
alert.getEditor.getText().trim match {
case i if !i.isEmpty => i + "_record.csv"
case _ => "NoName_record.csv"
}
}
private[this] def initDataStage(mainStage: Stage, scene: Scene): Stage = {
val stage = new Stage()
stage.setScene(scene)
stage.initOwner(mainStage)
//stage.initModality(Modality.APPLICATION_MODAL)
stage.setOnCloseRequest(e => {
voiceBox.requestShutdown()
println("Closing Stage Now...")
doSave(fileName)
})
stage
}
private[this] def withTimeAndSaveKeyCode(from:KeyCode): Unit = {
println("Pull trigger with " + from)
key.set(from.toString)
//如果没有启动保存进程,则启动,反之,则不启动,算作更改
if (!saving) {
edit.setVisible(false)
save.setVisible(true)
saving = true
val current = (Instant.now(), from)
val task = new Task[Double] {
override def call(): Double = {
//n s 后自动保存
TimeUnit.SECONDS.sleep(waiting.getText().trim.toInt)
//如果检测到更改,则以最后修改为准
val real = (current._1, key.get())
data.append(real)
println("Saved " + real)
saving = false
Platform.runLater(() => {
key.set("Waiting...")
save.setVisible(false)
edit.setVisible(false)
stage.setTitle(fileName + " [ Collected - " + data.length + " ]")
})
0.0
}
}
new Thread(task).start()
} else edit.setVisible(true)
}
private[this] def doSave(name: String): Unit = {
DataUtils.saveTo(Paths.get(name)) {
val sb = new StringBuilder
data.foreach(i => {
sb.append(i._1.toString).append(", ").append(i._2).append("\n")
})
sb
}
}
}
增加语音反应容错性
语音是基于模型算出来的,很显然,根据我的观察,对于南方的孩子,它们对于数字的发音很难被阿里云记录,包括各种奇怪发音的 2、6。为此,添加了一个机制,可以提供对应数字的各种可能的识别结果字典,通过这种配置文件来增加语音记录的容错性。
其会读入上文介绍的 yaml 文件,然后对比语音识别结果和此字典,以确定目标反应。
object VoiceRecognizerBox {
def readYamlToKeyVoiceMatchMap(path: Path): util.Map[String,util.List[String]] = {
if (!path.toFile.exists()) new util.HashMap[String, util.List[String]]()
else {
var fr: FileReader = null
val map = try {
fr = new FileReader(path.toFile)
val res = new Yaml().loadAs(fr, classOf[util.Map[String,util.List[String]]])
fr.close()
if (res == null) new util.HashMap[String, util.List[String]]()
else res
} catch {
case i: Throwable =>
i.printStackTrace(System.err)
new util.HashMap[String, util.List[String]]()
} finally {
if (fr != null) fr.close()
}
map
}
}
}
读取此 Map 的代码见 “整合到 Recorder 记录器” 部分。
尾巴
经过多线程并发读取语音文件、发送语音文件的优化,以及对于语音近义词容错机制的设置,在实际实验中,被试语音的收集率可以达到手动收集的 85% 及其以上。这无疑是令人振奋的,因为它解决了语音收集的一个很恼人的问题,节约了实验人员大量的时间。
最后夸奖一句,即便是每 2s 进行一次识别,阿里云也没有向我收费,实际上,只要在 10 个并发之内,调用此 API 的次数是无限的,只是 Token 会偶尔过期,需要手动更新罢了(大概一天一次)。然后再吐槽一句,国内这些公司的文档... 实在是不敢恭维,big-edian 编码这里我绕了好久,文档中从来没有一个地方讲编码这回事,真的是无语,至于讯飞的 API,那个更烂,烂到不能再烂。但是就计数而言,阿里云带动下的阿里巴巴,起码对开源做出了很大的贡献,这也是值得肯定的。
————————————————
2019-05-03 撰写本文